NetMiner AI 분석 리포트 : 노벨문학상, 국내 뉴스 여론은?
안녕하세요 사이람입니다.
지난 수요일(30일)에 News Data Collector가 News Data Collector Plus로 새롭게 업데이트 되었습니다.
News Data Collector Plus는 기존 News Data Collector의 국내 뉴스 기사 수집 기능뿐만 아니라 데이터 분석부터 'AI 분석 리포트 생성' 기능까지 제공하고 있습니다. 이로써 연구자들은 수집된 뉴스 데이터로 복잡하고 다양한 네트워크 분석 결과와 PPT 파일로 된 분석 리포트를 단 몇 번의 클릭만으로 확인하여 시간과 비용을 절감하고 효율적인 의사결정을 내릴 수 있게 되었습니다.
NetMiner News Data Collector Plus를 이용하여 국내 뉴스 기사 수집 및 분석을 진행하고 AI 분석 리포트 생성 결과 사례를 확인하는 시간을 갖도록 하겠습니다.
지난 10월 10일 저녁 8시(한국 시각) 스웨덴 한림원은 2024년 노벨문학상 수상자로 대한국 작가 ‘한강’을 선정했습니다. 이 같은 소식이 전해지자 국내 언론에서는 한강 작가의 노벨문학상 수상 소식에 대해 많은 기사를 보도했고 국내 독자들은 한강 작가의 도서 구매 열풍을 일으키기도 했습니다.

[사진:노벨 위원회]
이와 관련하여 국내 언론에서는 '노벨문학상'과 관련하여 어떤 주제들의 기사들을 보도했는지 NetMiner News Data Collector Plus로 한 번 확인해 보겠습니다.
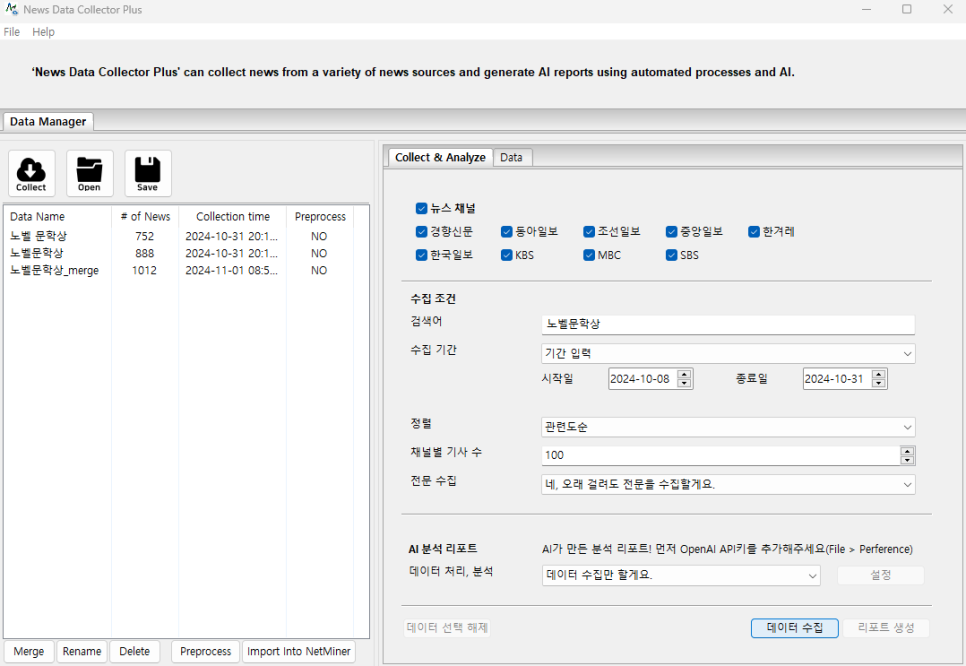
데이터 수집
1. 데이터 수집 조건
[데이터 수집, 조건]
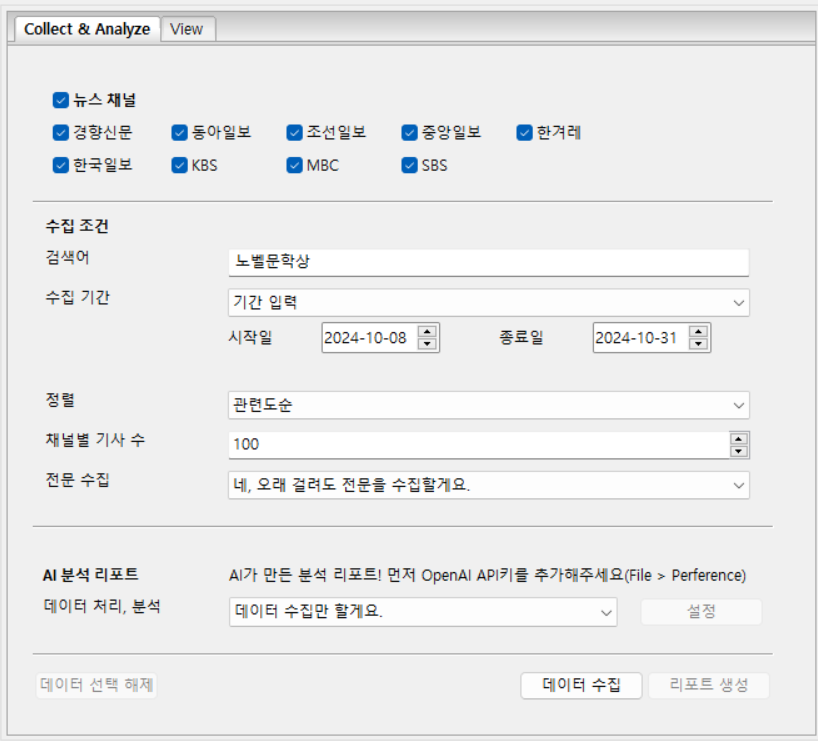
수집 키워드 : 노벨문학상, 노벨 문학상
수집 기간 : 2024-10-08 ~ 2024-10-31
정렬 : 관련도 순
채널별 기사 수 : 100
전문 수집 : 네, 오래 걸려도 전문을 수집할게요.
데이터 처리, 분석 : 데이터 수집만 할게요.
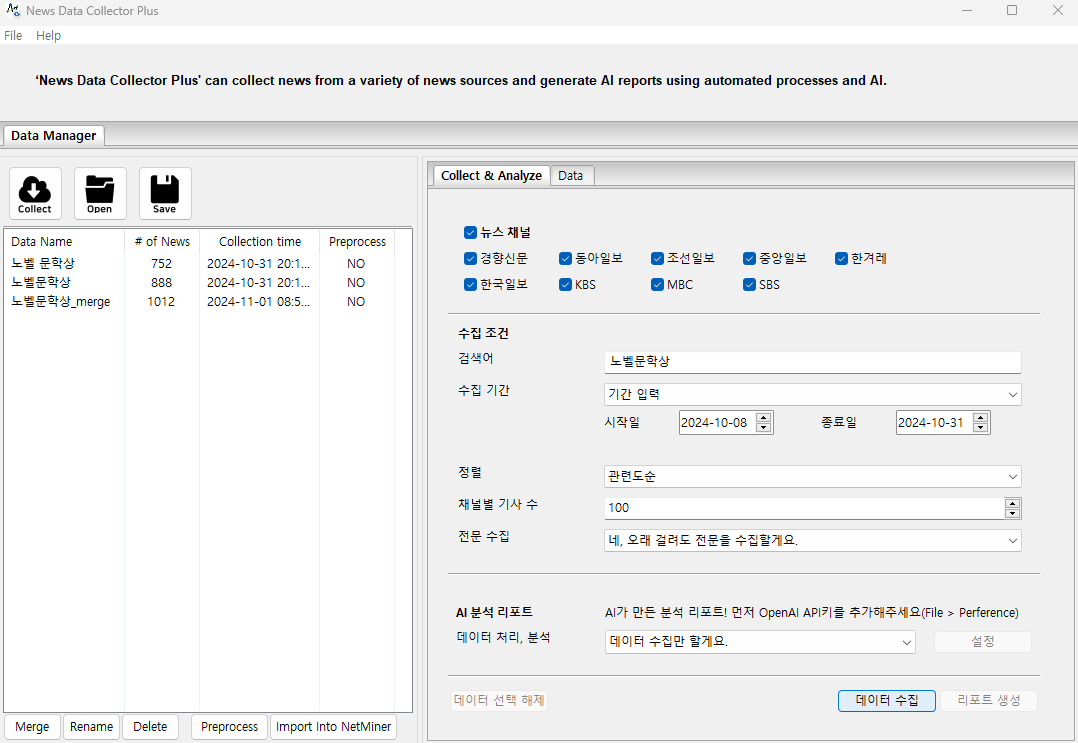
[데이터 수집 결과]
'노벨문학상', '노벨 문학상' 키워드로 각각 기사를 수집한 다음 최종적으로 merge 한 데이터를 이용하여 데이터 분석 및 AI 리포트를 생성하도록 하겠습니다.
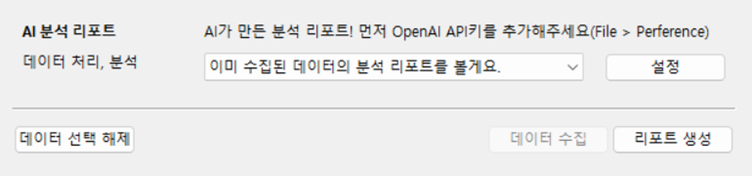
2. 데이터 분석 설정

[데이터 처리, 분석]
NetMiner News Data Collector Plus는 '기존에 수집한 데이터'로 분석 및 AI 리포트를 생성할 수 있고, '데이터 수집과 AI 리포트를 생성을 동시에 수행' 할 수도 있습니다. '이미 수집된 데이터의 분석 리포트를 볼게요.'를 선택하여 수집한 뉴스 데이터를 이용하여 AI 분석 리포트를 생성하도록 하겠습니다.
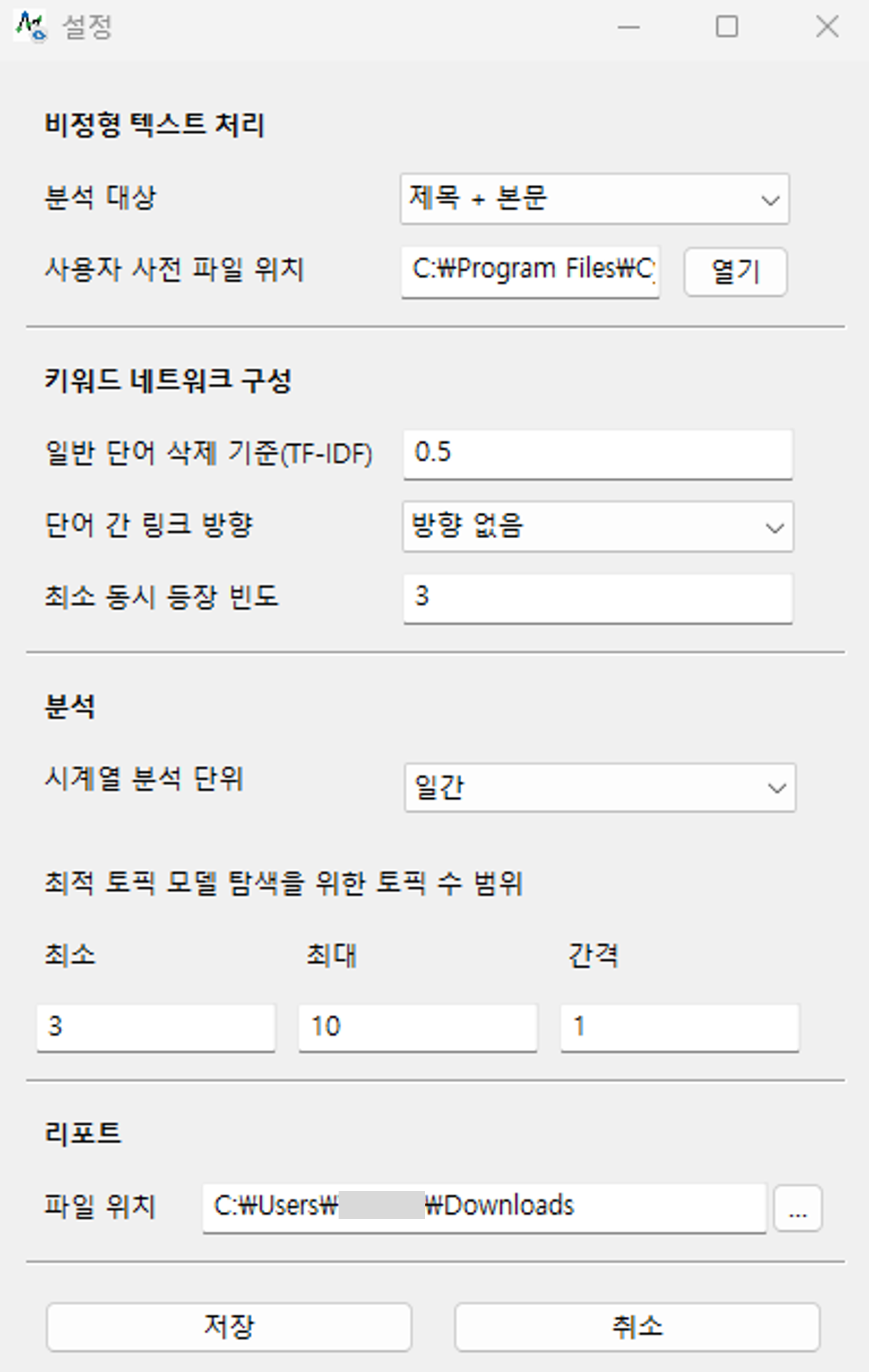
[설정 화면]
분석 리포트를 생성하기 전에 분석과 결과 생성에 필요한 여러 조건들을 설정해야 합니다. 크게 4가지 요소들을 설정해야 합니다.
비정형 텍스트 처리
분석 대상 선택 : 제목 + 본문
사용자 사전 파일 위치 : ㈜사이람의 분석 컨설팅 노하우를 기본으로 한 샘플 사전 파일을 제공합니다.
키워드 네트워크 구성
일반 단어 삭제 기준 : 0.5
단어 간 링크 방향 : 방향 없음
최소 동시 등장 빈도 : 3
분석
시계열 분석 단위 : 일간
최적 토픽 모델 탐색을 위한 토픽 수 범위 : 3 ~ 10
리포트
파일 위치 : AI 분석 리포트와 분석 결과의 저장 경로를 지정합니다.
AI 분석 리포트 결과 확인
1. 시계열 빈도 분석
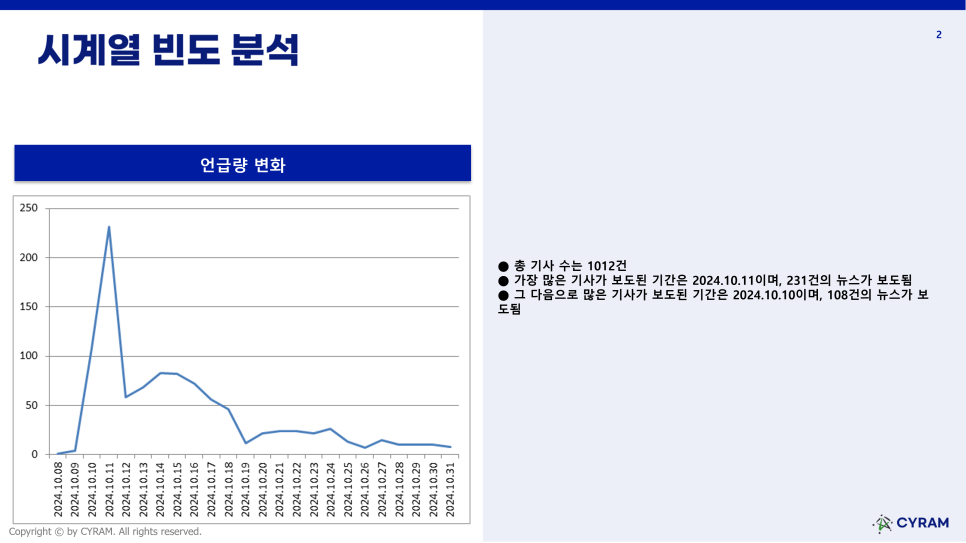

[시계열 빈도 분석-언급량 변화]
수집 기간(10.08 ~ 10.31) 일자 별로 노벨문학상 관련 뉴스 기사가 수집된 양을 확인할 수 있는 시계열 빈도 분석 그래프입니다. 총 수집된 기사 수와 가장 많이 보도된 시점의 기사 수집량과 두 번째로 많이 보도된 시점의 기사 수집량을 알려주고 있습니다.

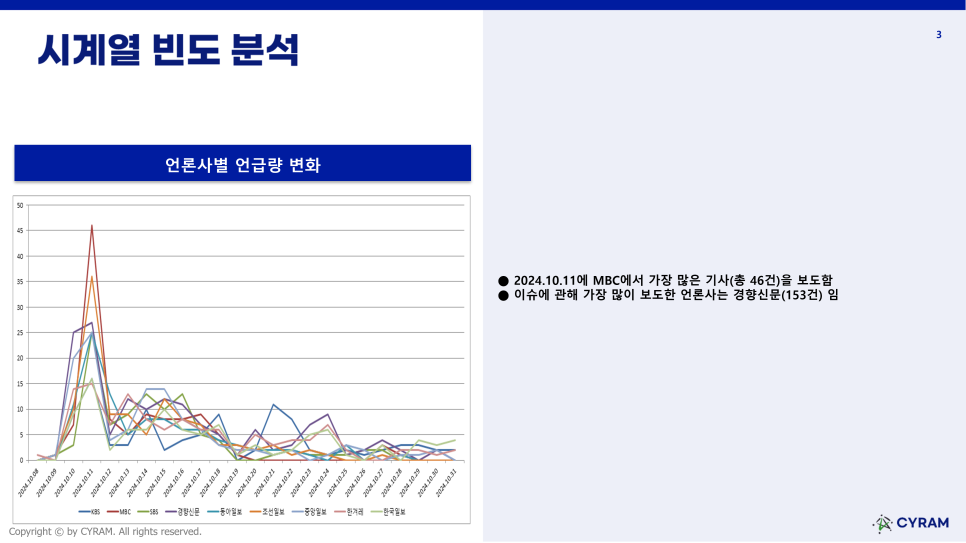
[시계열 빈도 분석-언론사별 언급량 변화]
두 번째 시계열 분석 결과에서는 각 언론사별 기사 수집량을 그래프로 보여주고 있습니다. 가장 많이 보도된 시점의 언론사와 해당 언론사의 기사 수를 알려주고 있습니다. 또한 수집 기간 동안 가장 많이 보도한 언론사와 해당 언론사에서 보도한 기사 수도 알려주고 있습니다.
2. 핵심 키워드 분석
핵심 키워드 분석 결과에서는 뉴스 기사에서 가장 자주 사용된 단어가 무엇인지, 단어 간의 연관관계가 어떻게 구성되어 있는지, 어떤 단어가 중요하게 사용되었는지를 파악할 수 있습니다.

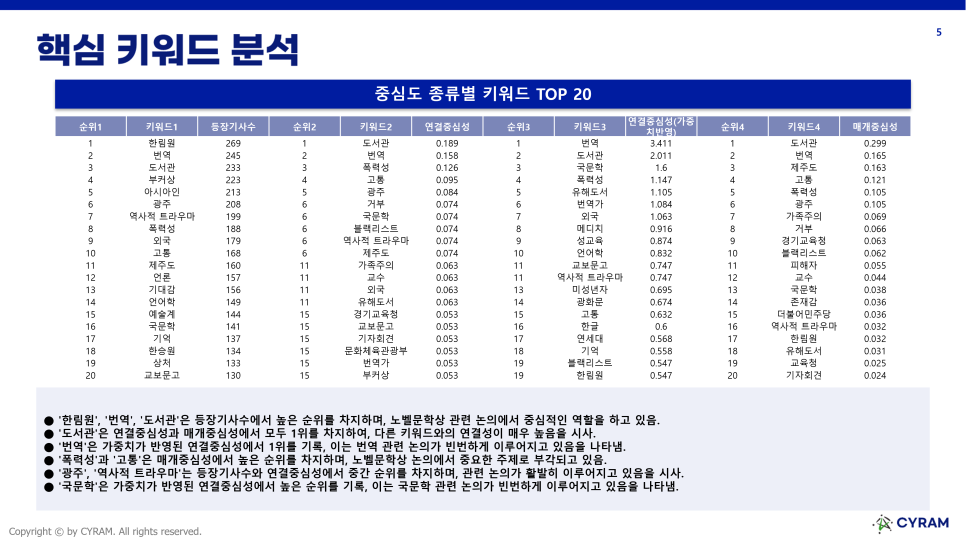
[중심도 종류별 키워드]
‘중심도 종류별 키워드 Top20’에서는 각 단어들의 등장 기사 수, Degree-Centrality(연결 중심성), Betweenness-Centrality(매개 중심성) 값을 확인하여 어떤 단어들이 중요하게 다뤄졌는지를 확인할 수 있습니다.
AI가 분석한 결과를 살펴보겠습니다. ‘한림원’, ‘번역’, ‘도서관’은 등장 기사 수에서 높은 순위를 차지했고, 특히 ‘도서관’은 연결 중심성과 매개 중심성에서도 모두 1위를 차지하여 다른 키워드와의 연결성이 매우 높다고 해석하고 있습니다.
‘번역’과 ‘국문학’은 가중치가 반영된 연결중심성에서 높은 순위를 기록했고 노벨문학상 관련 기사들이 번역과 국문학 관련 논의가 빈번하게 이뤄지고 있다고 해석했습니다.
‘폭력성’과 ‘고통’은 매개 중심성에서 높은 순위를 기록했고 노벨문학상에서 중요한 주제로 부각되고 있다고 해석한 것을 확인할 수 있습니다.


['폭력성' 연관 단어 네트워크 맵]
'연관 단어 네트워크 맵'에서는 특정 키워드의 Ego Network 시각화 결과를 확인할 수 있습니다. 특정 키워드와 연관이 있는 단어들 간의 연결 관계를 확인하여 단어들이 어떤 내용에서 사용되었는지를 확인할 수 있습니다.
‘폭력성’ 연관 단어 Top10에 대한 AI의 해석을 보면, ‘가부장제’ 키워드는 ‘폭력성’ 키워드와 가장 많이 연관되었고 이는 가부장적 사회 구조와 폭력성 간의 관계에 대한 논의가 활발히 이뤄지고 있다고 해석하고 있습니다.
두 번째로 많이 연관된 키워드인 ‘역사적 트라우마’에 대해서는 과거의 폭력적 사건들이 현재의 사회적, 개인적 트라우마로 이어지는 과정을 탐구하는 논의가 진행되고 있다고 설명하고 있습니다.
3. 이슈 분석
이슈 분석에서는 토픽 모델링 결과를 확인할 수 있습니다. 노벨문학상 관련 국내 기사들이 어떤 하위 주제로 분류되었는지 확인해 보도록 하겠습니다.

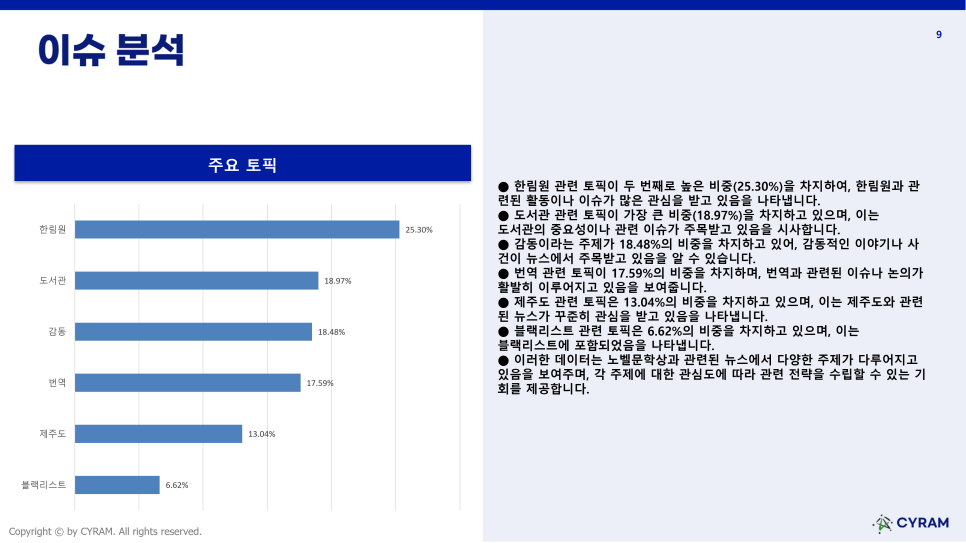
[이슈 분석-주요 토픽]
‘이슈 분석-주요 토픽’에서는 기사의 토픽 순위와 그 비중을 제시하고 있습니다.
총 6개의 토픽이 나타났으며, 가장 비중이 큰 토픽은 '한림원'으로 약 25%를 차지했습니다. 나머지 토픽들도 확인해 보면 2위는 ‘도서관’(약 19%). 3위는 ‘감동’(약 18.5%). 4위는 ‘번역’(약 18%). 5위는 ‘제주도’(약 13%). 6위는 ‘블랙리스트’(약 7%)를 차지하고 있습니다.

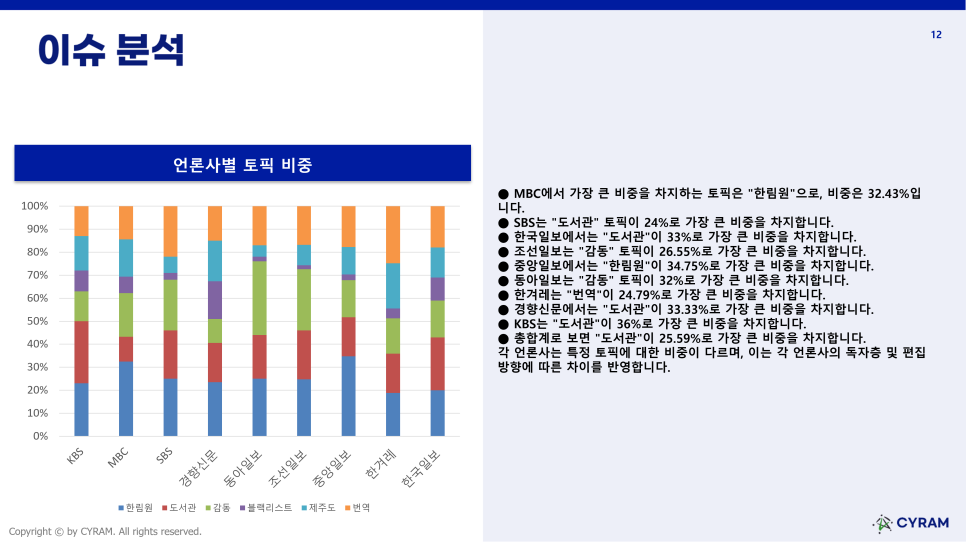
[이슈 분석-언론사별 토픽 비중]
‘이슈 분석-언론사별 토픽 비중’에서는 언론사별 토픽 비중을 다룬 시각화 결과를 다루고 있습니다. 각 언론사마다 어떤 주제를 주로 다뤘는지 한눈에 알아볼 수 있습니다.


[이슈 분석-'한림원' 토픽 키워드 네트워크 맵]
‘이슈 분석-토픽 키워드 네트워크 맵’에서는 각 토픽에 포함된 단어 간의 네트워크를 확인할 수 있고, 이로써 해당 토픽이 구체적으로 어떤 내용을 다루고 있는지 확인할 수 있습니다.
가장 많은 토픽 비중을 차지한 '한림원' 토픽에서 AI는 ‘폭력성’과 ‘고통’ 키워드가 연관 단어 수가 가장 높아 중요한 역할을 한다는 설명을 하고 있습니다. 또한 ‘언어학’과 ‘역사적 트라우마’ 키워드의 연관 단어 수도 많아서 학문적 및 역사적 관점이 강조되고 있다고도 설명합니다.


[이슈 분석-'번역' 토픽 키워드 네트워크 맵]
'번역' 토픽의 상위 연관 단어에 대한 AI의 해석을 보면, '번역가'와 '국문학' 키워드가 높은 연관 단어 수를 보여 번역의 질과 문학적 가치에 대한 논의가 활발하게 이뤄지고 있다고 설명하고 있습니다. 그리고 '한글'과 '언어학' 키워드는 번역의 언어적 측면과 한국어의 세계화에 대한 관심을 반영하고 있다고 해석하고 있습니다.
데이터 분석을 위한 가장 쉬운 방법, NetMiner
관심 있는 이슈에 대해 어떤 뉴스 기사들이 있었는지 궁금하시다면,
NetMiner 확장 프로그램인 News Data Collector Plus로 뉴스 데이터를 수집하고 즉석에서 AI 분석 리포트를 받아보세요.
뉴스 데이터를 쉽고 간편하게 수집하고, 다양한 텍스트 분석 결과와 AI의 해석이 포함된 리포트를 한 번에 확인할 수 있습니다.
NetMiner News Data Collector Plus 보러 가기 >>