NetMiner365를 활용한 그래프 분석과 머신러닝 웨비나 결과
2024년 NetMiner365를 활용한 그래프 분석과 머신러닝 웨비나
<2024 웨비나 Full Video>
2024년 웨비나 YouTube
안녕하세요, 사이람입니다.
2024년 5월 31일, 「NetMiner365를 활용한 그래프 분석과 머신러닝 웨비나 결과」 라이브 줌(zoom) 웨비나가 진행되었습니다.
이번 무료 공개 웨비나는 그래프 분석 & 그래프 머신러닝 및 7월 출시 예정인 NetMiner365에 대한 소개, NetMiner365 사용법 및
이를 활용한 그래프 머신러닝 분석 사례에 대해서 이야기를 나누는 자리였습니다.
대학(원)생, 교수 및 연구원, 초중고교 교사, 연구 기관, 정부 기관, 기업 등 넷마이너 분석 소프트웨어 서비스를 이용하고 계신 많은 분들이 이번 웨비나에 열정적으로 참여해 주셨습니다.
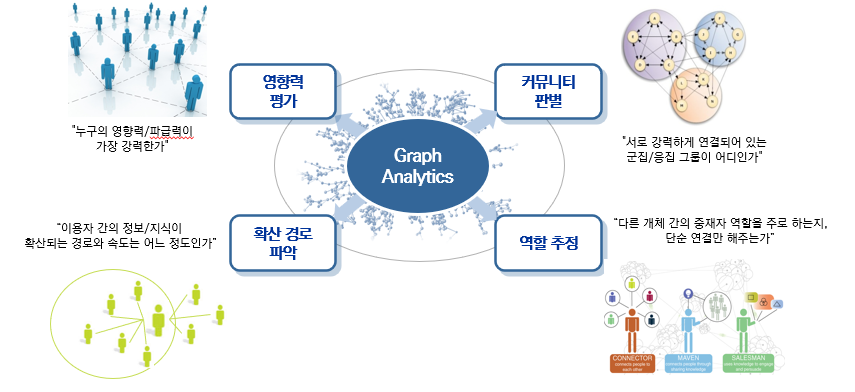
Graph Analytics 란?
그래프는 노드와 노드 간의 링크(상호작용, 연결)로 이루어진 구조로써 사물과 그들 간의 관계를 표현할 수 있는 데이터를 의미합니다.
그래프 분석은 분석가가 머신러닝의 정확도를 향상시켜 더욱 적절한 결정을 할 수 있게 도와줍니다.
- 그래프 분석의 주요 분석 지표
- 영향력 평가: 누구의 영향력이 가장 강력한지 평가
- 커뮤니티 판별: 서로 강력하게 연결되어 있는 군집/응집 그룹을 확인
- 확산 경로 파악: 정보/지식의 확산 경로와 속도 분석
- 역할 추정: 개체 간 중재자 역할 여부 평가
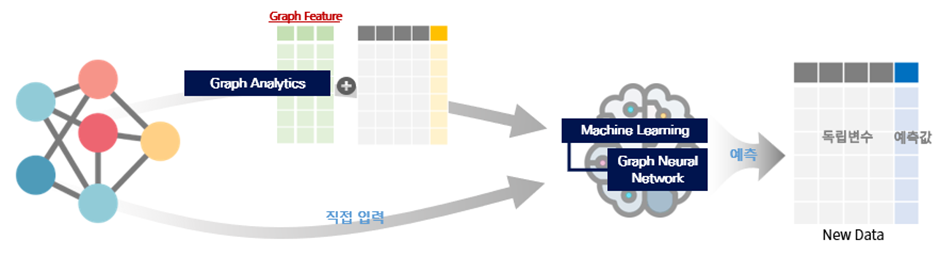
Graph Machine Learning 이란?
그래프 기반 머신러닝은 기존 데이터와 더불어 관계 데이터까지 활용하여 더욱 정확하고 정교한 예측을 가능하게 합니다.
일반적인 머신러닝 모델을 사용하기도 하지만 그래프 신경망(Graph Neural Networks, GNN)과 같은 특화된 모델을 사용할 수 있습니다.
- 그래프 기반 머신러닝의 목적
- 노드 분류(Node Classification)
- 링크 예측(Link Prediction)
- 그래프 분류(Graph Classification)
- 그래프 머신러닝 기술의 활용 분야
NetMiner365 란?
NetMiner365는 그래프 기반 머신러닝을 위한 온라인 데이터 사이언스 플랫폼입니다. 그래프 분석, 머신러닝, 그래프 머신러닝을 위한 데이터 구조와
데이터 준비 기능을 지원을 합니다. 그래프 & 차트 시각화, 통계 분석 기능을 통해 데이터 탐색이 가능하고 그래프 분석, 머신러닝, 그래프 머신러닝 알고리즘과
파이프라인을 다양하게 제공합니다.
NetMiner365는 클라우드 기반의 온라인 플랫폼으로 다양한 기기에서 웹을 통해 접근이 가능합니다. 클라우드 자원(CPU, RAM)을 활용하므로
개인 하드웨어의 제약을 극복하고 복잡한 분석이 가능합니다.
NetMiner365는 클라우드 기업이 제공하는 서비스의 정보보호 기준 준수 여부를 평가하고 인증하는 CSAP(Cloud Security Assurance Program) 인증을 받아
더욱 안전한 데이터 분석 환경을 제공합니다.
또한 NetMiner365는 기존의 NetMiner와 연동하여 데이터 전처리 및 분석, 그래프 머신러닝 분석을 수행할 수 있습니다.
- NetMiner365의 주요 특성
- Self-Service Machine Learning: 몇 번의 클릭만으로도 간단하게 머신러닝을 구현
- Full-Featured Graph Analytics: 그래프 분석을 위한 데이터 구조 및 준비/시각화 기능/분석 알고리즘을 제공
- Cutting-Edge Graph Machine Learning: 최신의 그래프 머신러닝 알고리즘과 다양한 머신러닝 파이프라인을 지원
- NetMiner365로 활용 방안
- Machine Learning: 데이터 분류, 요인 이해 등의 문제를 해결
- Graph Analytics
- 중요성 스코어링(Importance Ranking): 가장 중요한 개체가 무엇인지 파악
- 커뮤니티 파악(Community Detection): 상호 밀접한 관계를 맺고 있는 군집 파악
- 유사 개체 분류(Node Similarity): 유사한 역할과 위치에 있는 개체를 분류
- Graph Machine Learning: 노드 분류, 링크 예측과 같은 문제를 해결
분석 사례1. 트위터 그래프 머신러닝 사례
정치적 의견을 표현하는 트위터 데이터를 활용하여 후보 A에 대한 유저의 지지/반대 성향 예측하고자 합니다.
유저가 자주 사용하는 해시태그와 유저 간 리트윗 관계를 학습하여 지지/반대 성향을 분류하는 모델을 생성하고 성능이 좋은 학습 모델을 적용하면
지지/반대 성향을 알 수 없는 유저들의 성향을 파악할 수 있습니다.
- 수집개요
- 수집 기간: 2022.01.17 ~ 2022.02.09
- 수집 채널: 후보 A의 트위터
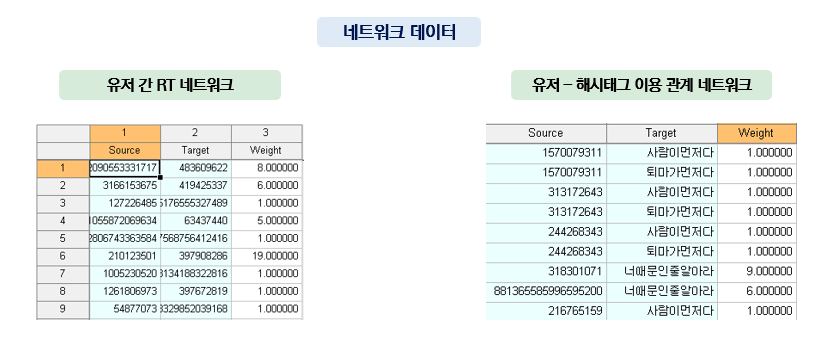
- 분석 데이터: 4,823명의 유저, 12,701개의 리트윗 네트워크 링크, 102개의 해시태그
NetMiner Extension을 이용해서 데이터를 수집하면 자동으로 네트워크 형태로 구조화되어 입력이 됩니다. 이 중 유저 간 RT 네트워크 및 분석 결과를 모델 학습 시 독립변수로 이용하고
유저-해시태그 이용 관계 네트워크를 활용하여 유저의 feature 형태로 변환한 뒤 모델 학습 시 독립변수로 이용합니다.
이렇게 NetMiner4를 활용하여 트위터 유저의 성향 분류 및 예측을 위한 관계 기반의 유저의 속성을 만들어 낼 수 있고 이를 NetMiner365에 적용할 수 있습니다.
- 분석 결과 - 기초 통계 & Graph Analytics
- 네트워크 시각화: 지지 성향이 비슷한 이용자들끼리 연결
커뮤니티 분석: 1번 커뮤니티에 속한 이용자는 주로 후보 A를 지지, 2번 커뮤니티에 속한 이용자는 주로 후보 A를 반대
- 너때문인줄알아라’ 해시태그를 사용한 이용자는 주로 후보 A를 지지하는 이용자, 사용하지 않은 이용자는 반대하는 이용자
- 트리맵: 유저 별로 지지/반대 여부에 따라 해시태그 이용 여부의 차이가 확인
- ‘파이 차트(Pie Chart): 종속 변수(지지, 반대)의 타겟 값이 있는 유저는 반대하는 유저의 비중이 더 큼
- 분석 결과 - Graph Machine Learning유저의 정치 성향 분류를 위해 4가지 모델을 학습한 결과입니다.
트위터 유저의 성향을 예측하는데 있어서 RT 네트워크 분석 결과를 feature로 사용하거나 직접 학습할 때 예측 성능이 향상될 수 있음을 알 수 있었습니다.
머신러닝 학습 방법을 사용한 모델을 비교했을 때, 커뮤니티 변수의 포함 여부가 정확도를 높이는 데 영향을 주는 것을 확인할 수 있었습니다.
GCN 학습방법을 이용해서 커뮤니티 변수 외에 그래프 자체를 학습하는 것이 정확도를 향상시키는 데 기여했다고 볼 수 있습니다.
그러므로, 어떤 데이터가 분류하고자 하는 특정 대상에 대한 속성 정보가 있고, 그 특정 대상 간의 연결관계 데이터가 존재했으며,
그래프 또는 네트워크 기반 Feature가 분류 예측에 영향을 끼칠 수 있다는 것을 확인할 수 있었습니다.

트위터 유저 성향 분포
NetMiner365의 모델 저장 및 Deploy 기능을 활용해서 앞서 성능이 높게 나타난 분류 모델을 저장하고 배포할 수 있습니다.
배포된 모델을 이용하여 Test Data 유저의 정치 성향을 예측을 한 결과, A 후보자를 언급한 트윗을 리트윗하는 사람들은 지지하는 성향보다는 반대하는 성향이 더 많았다고 할 수 있습니다.
분석 사례2. 블로그 그래프 머신러닝 사례
그림 출처: Adamic, L.A., & Glance, N.S. (2005)
미국 정치 블로그의 정치 성향을 2가지 방식으로 예측하고자 합니다.
첫 번째, 블로그 간 링크 관계에서 그래프 분석으로 노드의 feature를 추출 한 다음 특정 블로그의 정치 성향을 분류하는 모델을 생성하여 파악.
두 번째, 블로그 간 링크 관계 그래프를 학습한 임베딩으로 노드의 feature를 추출하여 특정 블로그의 정치 성향을 분류하는 모델을 생성하여
노드의 feature 없이 그래프만 있을 때 그래프 특성을 활용해서 예측이 가능한지 확인.
- 수집 개요
- 수집 기간: 2004년
- 수집 채널: 미국 정치 블로그
- 분석 데이터: 블로그 수 1,490개, 링크 수는 19,025개(블로그의 정치성향 라벨링은 블로그 디렉토리에 분류되어 있는 것을 활용)
- 분석 결과 - Graph Analytics
 분석 결과, 응집 그룹 분석 중 하나인 Louvain 커뮤니티 분석 방법과 역할 그룹 분석 중 하나인 SimRank 분석 방법이 진보/보수를 가장 잘 예측했습니다.
분석 결과, 응집 그룹 분석 중 하나인 Louvain 커뮤니티 분석 방법과 역할 그룹 분석 중 하나인 SimRank 분석 방법이 진보/보수를 가장 잘 예측했습니다.각종 Centrality 분석도 진행했지만 Centrality는 머신러닝 모델 정확도를 높이는데 전혀 기여를 하지 않았습니다.
즉, 진보와 보수를 나누는 것이 네트워크 내에서 똘똘 뭉치는 성질과 관련이 있고 소수를 중심으로 연결을 생성하는 성질과는 관련이 떨어짐을 짐작할 수 있었습니다.
다시 말해, 연결이 많다고 해서 진보, 연결이 적다고 해서 보수로 나뉘는 것이 아니라 진보는 진보끼리 보수는 보수끼리 똘똘 뭉치는 구조라는 의미입니다.
- 분석 결과 - Graph Machine Learning (Graph Feature 이용)


블로그의 정치성향을 가장 잘 분류하는 머신러닝 모델은 Naïve Bayes와 MLP이고, 정확도는 94%입니다.
MLP 모델에서의 변수 중요도를 살펴보면 커뮤니티 변수가 SimRank 변수보다 중요도가 높은 것을 확인할 수 있습니다.
- 분석 결과 - Graph Machine Learning (Node2Vec 이용) 이번에는 노드의 feature 없이 Node2Vec을 이용하여 그래프 데이터를 학습하고 그래프의 특징을 반영한 2차원으로임베딩하여 생성한 변수를 독립변수로 사용했습니다.
이번에는 노드의 feature 없이 Node2Vec을 이용하여 그래프 데이터를 학습하고 그래프의 특징을 반영한 2차원으로임베딩하여 생성한 변수를 독립변수로 사용했습니다.블로그의 정치성향을 가장 잘 분류하는 머신러닝 모델은 Logistic Regression, CART, SVM, MLP, Random Forest,
Gradient Boosted Trees 이고, 정확도는 96%입니다.
앞의 그래프 분석 결과 변수를 이용한 학습 모델과 비교했을 때, 여러 머신러닝 알고리즘 학습 모델의 정확도가 높아진 것을 확인할 수 있습니다.
변수 중요도에서 V1, V2가 그래프의 어떤 것을 의미하는지 확실하게 알 수 없습니다. 하지만, 그래프 분석을 통해 얻은 feature는
분석 알고리즘의 원리를 알기에 그래프의 성격을 이해할 수 있다는 장점이 있습니다.
반면, Node2Vec을 통한 임베딩 feature는 그래프의 어떤 성격을 의미하는지 이해하기 어려우나, 인간이 이해하기 어려운 특징까지
그래프를 학습한 결과 정보를 담고 있으므로 가치가 있습니다.
많은 분들의 관심 덕분에 성공적으로 웨비나를 마칠 수 있었습니다. 보내주신 의견은 소중히 반영하여 앞으로 더욱 쉽고 편리하게 프로그램을 사용하실 수 있도록 노력하겠습니다.
- 이번 웨비나에 참석하지 못하셨더라도, 누구나 2주 간 체험을 신청하실 수 있습니다. NetMiner365 홈페이지에 접속하시면, 신청서 작성 및 회원 가입이 가능합니다.
- NetMiner + Extension, NetMiner365, 온라인 교육, 전문가 컨설팅 등을 개별 이용 대비 최대 35% 할인된 금액으로 이용할 수 있는 플랜이 제공됩니다(* 방문 교육은 별도 추가 기능).
- 6개월 또는 1년 중 기간 선택이 가능하고, 월 결제 옵션도 가능합니다.
- NetMiner News Data Collector(뉴스 데이터 수집기)를 이용한 교육 과정이 신규 개설되었습니다. 뉴스 데이터 수집부터 분석 결과 해석까지, 단계별 상세한 실습을 통해 실전에 바로 활용이 가능합니다.
자세한 내용은 본사에 문의하시기 바랍니다.
감사합니다.
News Data Collector 교육 과정 바로가기>>