[NetMiner] 제주에서 날아온 소식! 제주 지역 인스타그램 분석
'떠나요~ 둘이서~ 모든 걸 훌훌 버리고~♪'
이 노래에서 주인공이 떠나고 싶은 곳은 어딜까요?? 바로 국내 대표적인 여행지 중 하나인 제주도 입니다!
오늘은 제주도에서 업로드된 인스타그램의 포스트(Post)를 분석한 결과를 소개해드리려고 합니다.
아시다시피, 인스타그램은 사진을 업로드할 때 사진의 위치를 자동으로 읽거나 또는 이용자가 원하는 지역을 지정하여 업로드 할 수 있습니다.
즉! 특정 지역에서 게시된 포스트만 볼 수 있다는 말이죠!
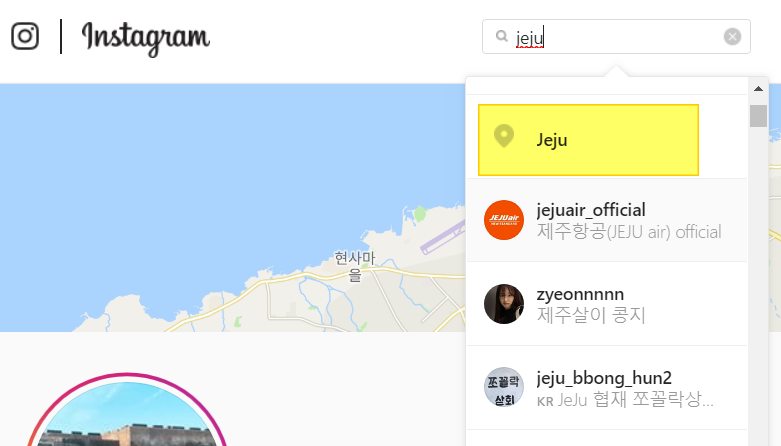
NetMiner의 확장프로그램인 SNS Data Collector(이하 SDC) 는 대표적인 소셜 빅데이터인 트위터, 페이스북, 유튜브, 인스타그램의 데이터를 수집할 수 있습니다.
그리고 인스타그램에서는 포스트의 위치 정보를 활용하여 데이터를 수집할 수 있습니다.
이번에는 말씀 드린 것처럼 제주도 지역의 유명 관광 명소에서 올라온 포스트들을 수집하였습니다. 물론 포스트 뿐만 아니라 인스타그램 댓글도 수집/추출할 수 있습니다 :)
검색 지역은 Jeju 와 대표적인 관광지인 성산일출봉, 협재해변, 천지연폭포, 애월해변, 비자림, 주상절리대 이며, 각각의 검색어로 수집한 후, Merge 버튼을 클릭해서 모든 포스트를 1개로 통합하였습니다.
데이터 수집이 세상에서 제일 쉬웠어요~!
- SDC의 Instagram Collector(인스타그램 수집기)에서 수집 기준으로 Location(위치)를 선택하고 지역 이름만 넣으면 끝! -
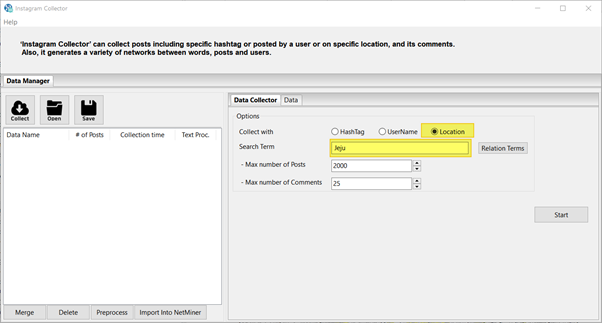
NetMiner에 가져와서 엑셀로 저장한 후(Import into NetMiner → Posts 데이터셋을 엑셀로 Export), 그 중 5.23~29일까지의 1주일 간 포스트를 분석해 보았습니다.
혹시 NetMiner 에 비정형 텍스트 데이터를 입력하면, 자동으로 사용된 단어가 추출된다는 사실 알고 계신가요?
기존의 여러 연구에서 사용되었던 형태소 분석용 도스 프로그램인 krkwic 처럼 NetMiner 도 형태소를 추출하고 품사를 판별합니다. 더하여 사용자 사전 기능을 제공하여 유의어(Thesaurus) 및 고유명사 처리, 스팸 문서 제거도 쉽게 할 수 있습니다. 그리고 사용 빈도/TF-IDF 등도 자동으로 계산해줍니다.
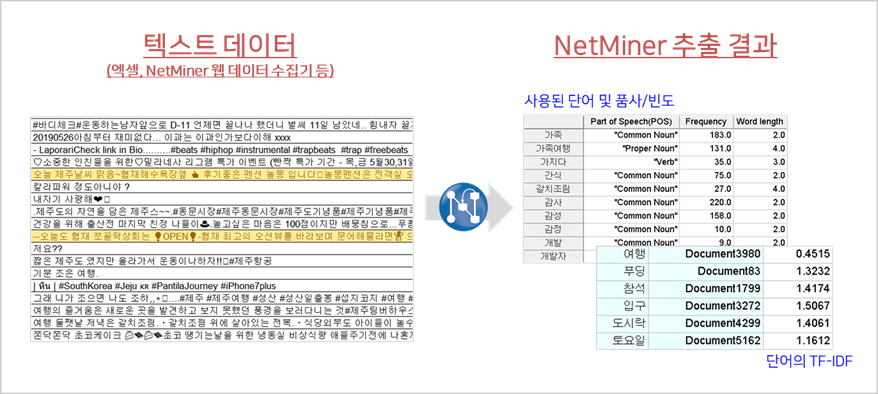
1) 수집된 포스트에 대한 기초 통계
① 요일/시간별, 위치별 포스트 수
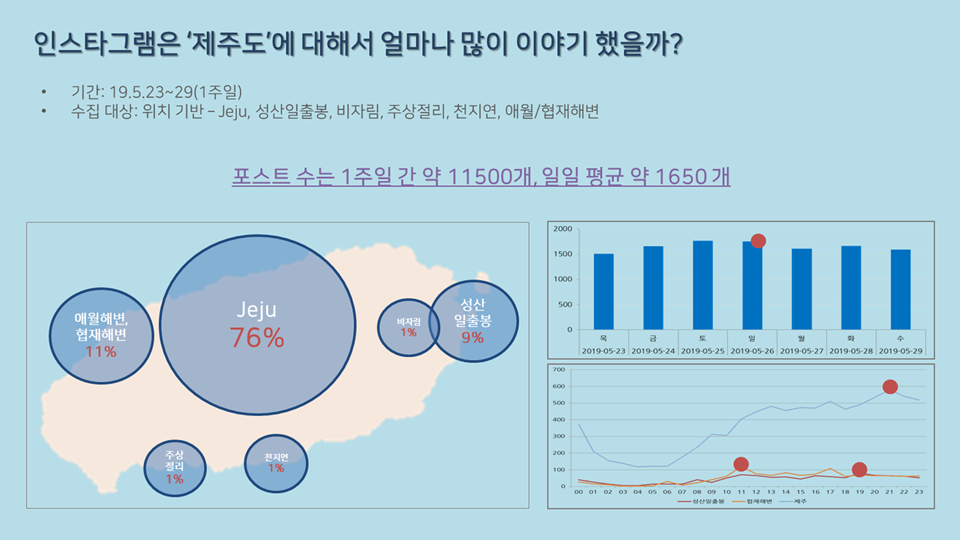
우선 1주일 동안 수집된 포스트는 약 11500개였고, 일평균 1650 개의 포스트가 수집된 것을 확인할 수 있었습니다.
대부분 'Jeju' 위치에서 게시되었거나 촬영된 포스트가 대부분이었고, 그 다음으로 애월/협재 부근과 성산일출봉 부근에서 게시된 포스트가 많았스니다.
애월/협재 지역은 #봄날 카페, #몽상드애월 과 같은 유명한 인스타 감성의 힙한 카페와 음식점이 소개되면서, 인스타 이용자들의 방문도 꽤 많았던 것 같습니다 :)
요일별로는 일요일에 가장 많은 포스트가 수집되었고, 목요일에 가장 적은 포스트가 나타났습니다.
그리고 가장 많이 포스트가 올라온 시간은 일정이 끝나고 조금 여유로워질 때쯤인 밤 9시였습니다.
다만 관광 스팟에 따라 다소 차이가 있었는데, 협재해변은 오전 11시와 오후 5시, 성산일출봉은 저녁 7시쯤에 올라온 포스트가 가장 많았습니다.
② 포스트 게시 건수와 요인
이번엔 포스트 수와 평균기온, 미세먼지(PM10) 지수가 연관이 있는지 확인하기 위해 상관 분석을 해보았습니다.
(NetMiner 의 Statistics >> Correlation 분석)
※ 날씨 및 미세먼지 정보 출처: 기상청, 에어코리아

포스트 수는 평균기온이 높을 수록, 미세먼지 지수가 낮을 수록 많았던 것을 확인할 수 있었습니다.
즉, 포스트 수는 평균기온과 미세먼지와 상관성이 있다는 거~!
그리고 평균기온과 미세먼지 지수도 양의 상관 관계에 있는 것으로 나타났습니다.
(다만, 1주일이라는 짧은 기간이라는 점, 포스트 수의 증감 요인으로 요일도 있을 수 있다는 점을 감안해주세요^^)
2) 광고성 포스트 비율
여기에서는 ① 포스트 내용이 완전히 같고, 글자 수가 20자 이상 또는 ②'문의', '휴무' 라는 단어를 포함한 포스트를 광고글로 정의하였습니다.

그 결과 수집된 포스트의 약 19%가 광고글로 분류되었습니다. 광고글로 분류된 포스트는 이후 분석에서는 제외하였습니다.
어떻게?! Text Process 중 Document Filtering(Spam Word - 스팸 필터) 기능을 활용해서!
Document Fltering 은 사용자 사전 중 하나로 등록된 단어를 포함하는 문서, 글을 제외하는 기능입니다.
즉, '문의', '휴무' 라는 단어를 스팸어(Spam Word)로 등록해주면 해당 단어를 포함한 포스트는 아예 제외하고 NetMiner에 불러옵니다.
엑셀의 필터 기능은 이제 더 이상 그만!
3) 해시태그 분석
인스타그램의 특징 중 하나는 해시태그의 사용입니다.
트위터도 해시태그를 사용하지만, 인스타그램은 포스트의 대부분이 해시태그로만 구성되어 있는 경우가 많습니다.
그래서 형태소로 분리되지 않고, 해시태그 자체를 고유명사로 처리하여 분석하려는 경우가 있죠?
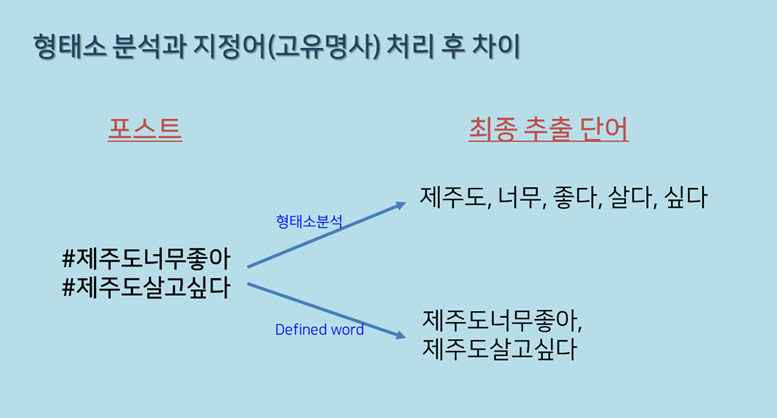
그럴 때는 Preprocess 에서 'Add Hashtags to Defined Words' 만 체크해주면, 해시태그가 고유명사로 등록됩니다.

트위터의 해시태그도 역시 SDC 에서 수집 후, Defined Words 에 해시태그들을 등록해주면, 이용자들이 사용한 해시태그에 대해서만 분석을 해볼 수 있겠죠?
그러면 제주도 지역에서 가장 많이 사용된 해시태그는 무엇이었을까요?
제주, 제주도를 제외하고 가장 많이 사용된 해시태그는 여행이었습니다.
분류해보면 여행명소 이름(협재해수욕장, 성산일출봉), 여행에 대한 묘사(여행, 좋다, 일상, 오늘), 음식/식사(맛집,맛있다, 먹스타그램, 카페), 날씨(비,날씨), 인스타그램 관련 해시태그(맞팔, 선팔, 소통) 에 대한 해시태그가 많이 사용된 것을 알 수 있습니다.

4) 포스트 내용 분석
이번에는 해시태그를 단어(형태소)로 쪼개어 포스트의 전체 텍스트를 분석해봤습니다.
① 단어 빈도 분석
가장 많이 쓰인 단어를 살펴볼까요?

역시 여행에 대한 묘사(여행,일상,오늘,바다,좋다,보다), 인스타그램 해시태그와 관련된 단어(스타그램, 소통 등), 음식/식사(먹다, 맛집, 카페, 흑돼지 등) 가 많이 사용되었습니다.
그렇다면, 가장 많이 사용된 형용사와 동사는 무엇이었을까요? 형용사와 동사로 분류된 단어만 추출하여 보았습니다.
감정 표현에 가장 많이 사용된 단어는 좋다, 맛있다, 예쁘다(이쁘다) 였습니다. 형용사를 통해 사람들이 표현한 감정을 분석해 볼 수 있었습니다.
그리고 자주 사용된 동사는 먹다, 보다, 찍다, 놀다, 사다 등 이었습니다.
역시 제주도는 보고, 찍고, 맛보고, 즐기고?!

② 관심 있는 단어의 연관(주변) 키워드 분석(텍스트 네트워크, 언어 네트워크 분석)
최근 여행을 통해 '휴식'을 얻고 싶어하고, '먹방' 프로그램처럼 먹고 즐기는 여행 트렌드가 대세죠?
이런 최근의 여행 트렌드를 설명하는 단어들의 연관 키워드를 한 번 볼까요?
NetMiner 의 Tools >> Word network 에서 간단히 주변에 자주 등장하는 단어끼리 링크를 만들어서, 키워드 네트워크(단어 동시출현/공출현 네트워크, Co-occurrence network)를 만들 수 있습니다.
그리고 특정 단어의 에고 네트워크(Ego Network)를 추출하면 간단하게 연관 키워드를 확인할 수 있습니다.
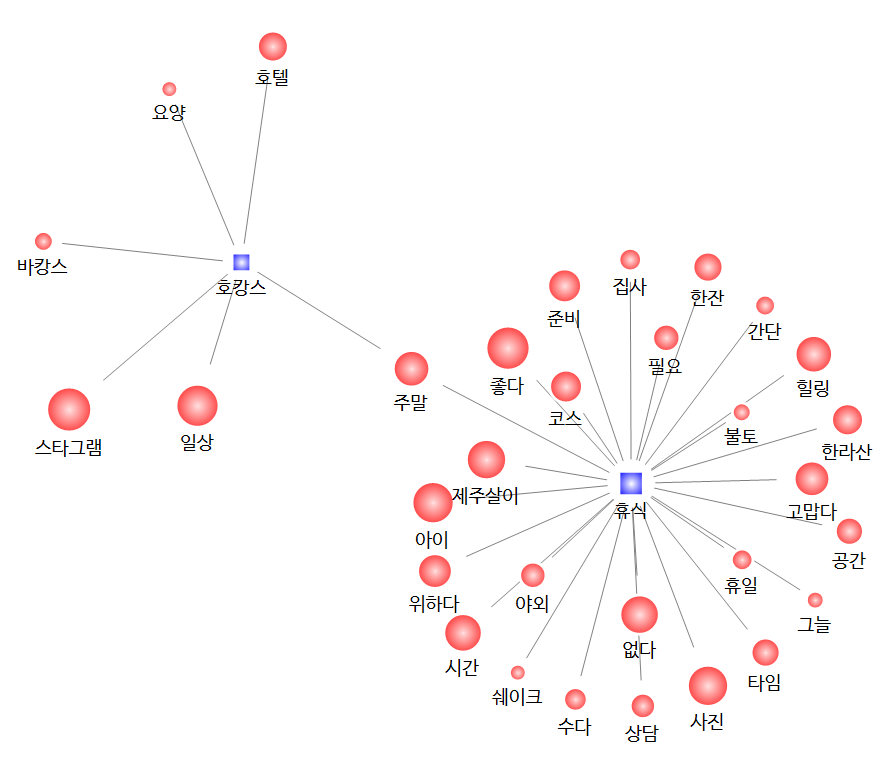
먼저, 휴식/호캉스와 함께 사용된 단어들입니다. 힐링, 좋다, 아이, 시간 등의 단어가 눈에 띄네요 :)
또한 제주살이, 일상 이라는 단어를 통해 단기 여행이 아닌 '현지인처럼 살아보기'에 대한 단어도 보입니다.
휴식을 통해 진정한 힐링을 찾는 여행을 원하는 요즘 트렌드를 그대로 보여주고 있습니다.
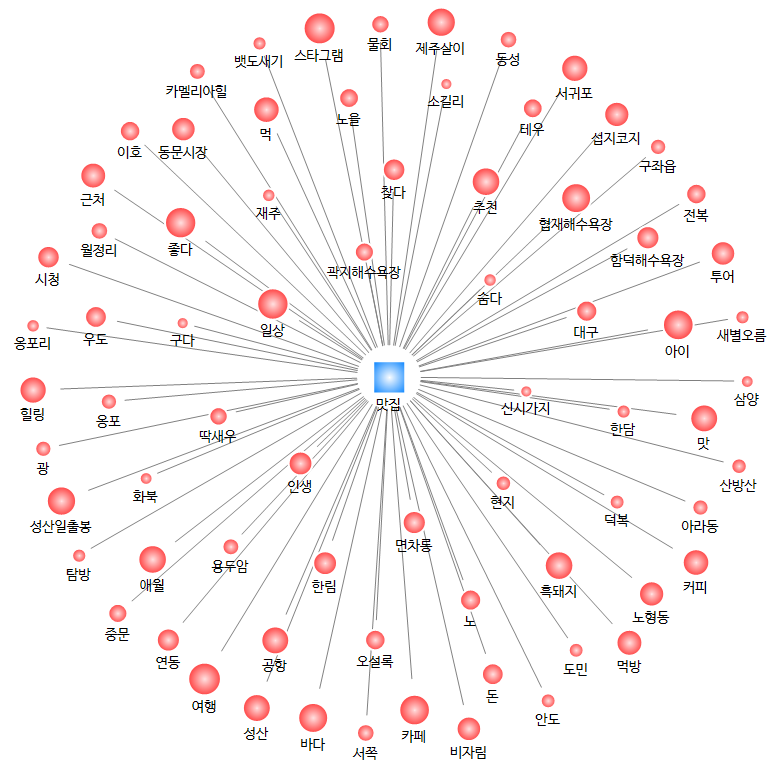
이번에는 '맛집'의 연관 단어들입니다.
주변 단어들을 살펴보면, 흑돼지, 딱새우 등 제주산 식재료에 대한 단어, 맛집 위치에 대한 단어, 카페 관련 단어 등이 나타나는 것을 알 수 있습니다.
그리고 맛집 주변에도 '힐링' 이라는 단어가 등장하는 것이 조금 흥미롭습니다.
또한 인스타에서는 OO스타그램 이라는 해시태그를 붙이는 게 일반적인데요,
제주에 대한 포스트에서는 어떤 '스타그램' 들이 사용되었는지 한 번 확인해보겠습니다.
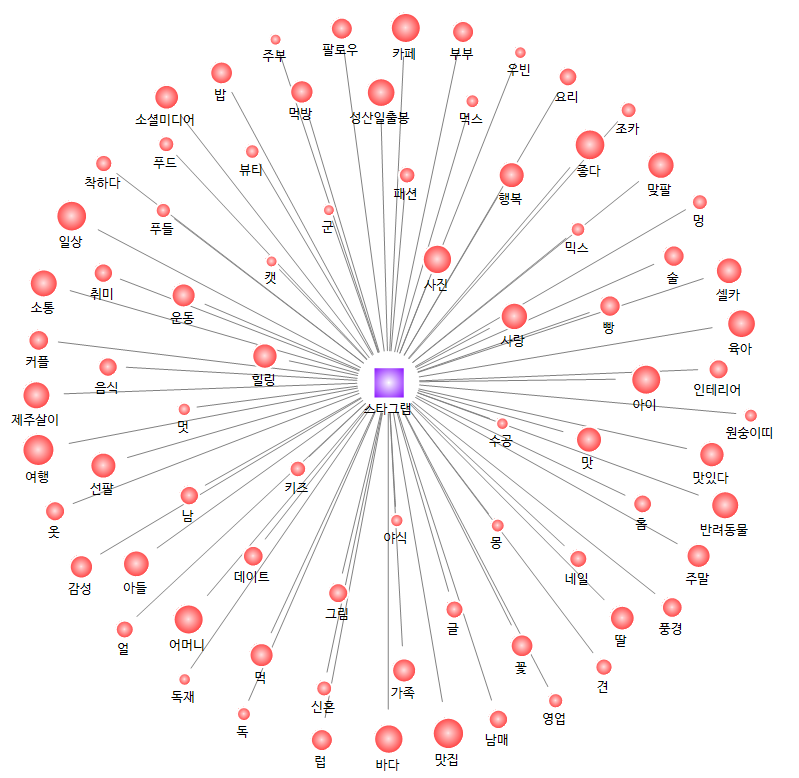
가장 많이 사용된 '스타그램'은 일상스타그램, 여행스타그램, 먹스타그램, 셀카스타그램, 육아스타그램 이었습니다.
③ 토픽 분석
토픽 분석(토픽모델링)은 대용량의 문서, 글, 소셜미디어, 논문 등에서 사용된 키워드를 주제별로 클러스터링하고, 동시에 문서도 주제별로 분류해주는 분석입니다.
대표적인 토픽 모델링 방법으로는 LDA 가 있는데요,
NetMiner 에도 이 LDA 가 포함되어 있다는 사실! Python, R 을 활용하여 분석하는 것과 달리, 클릭 몇 번만 하면 분석 리포트가 산출됩니다.
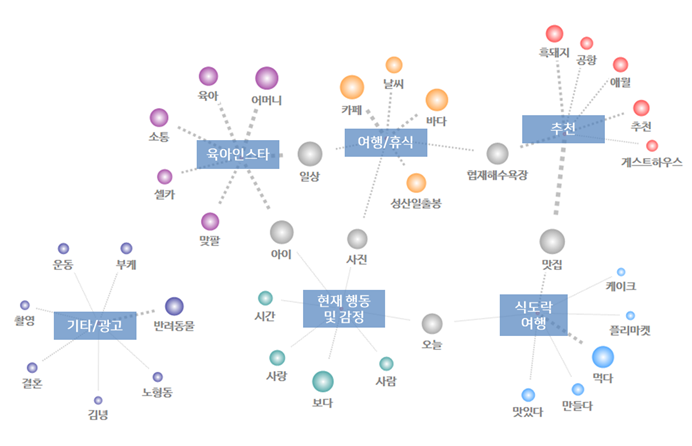
토픽 분석을 하기 전, TF-IDF 가 0.6 미만인 단어를 제외하였습니다
TF-IDF 는 대부분의 문서에서 사용될 수록 값이 낮기 때문에 TF-IDF 가 낮은 단어를 제외하면, 검색 키워드, 일반적인 단어를 쉽게 삭제할 수 있습니다 :)
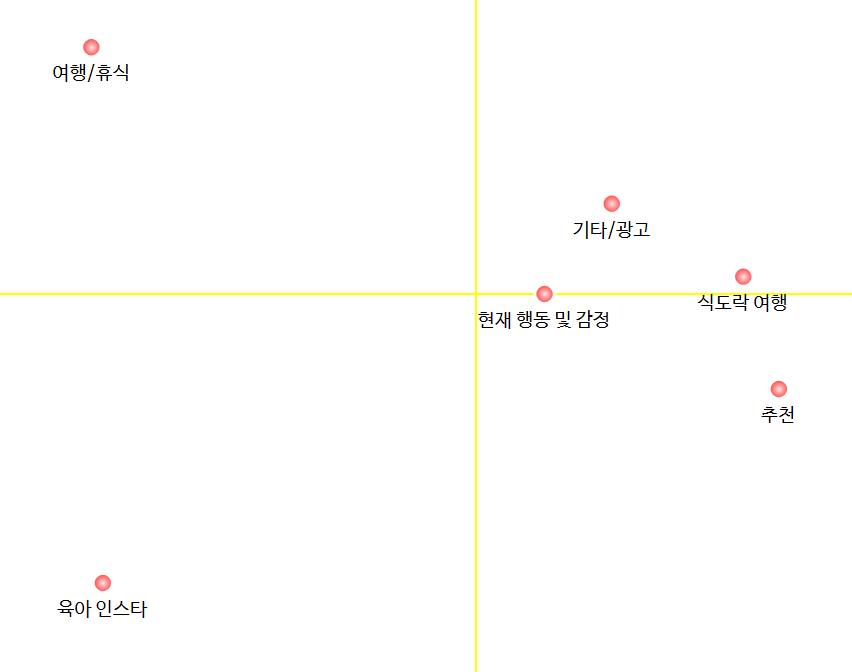
결과적으로, 아래와 같이 6개의 토픽이 추출되었습니다.
<토픽 추출 결과>
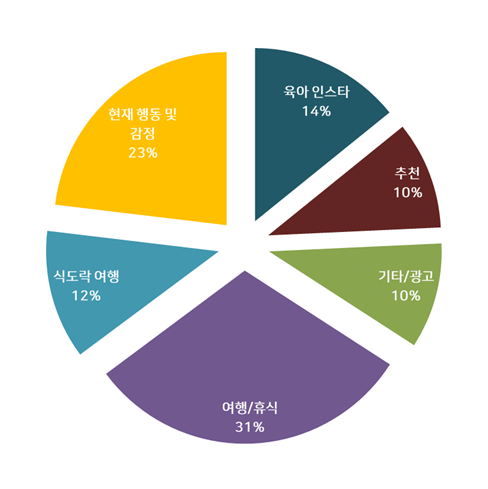
<토픽 비중>
토픽 분석은 키워드 분류 뿐만 아니라 문서도 분류해줍니다.
즉, 토픽에 따라 포스트를 분류했는데요, 그 결과 '여행/휴식'과 '현재 행동 및 감정'에 대한 포스트가 가장 많았던 것을 알 수 있었습니다.
역시 인스턴트(Instant)과 텔레그램(Telegram)이라는 단어를 조합하여 시작한 인스타그램 답네요 :)
| NetMiner 자동 토픽 분석 플러그인을 활용하면, 클릭 몇 번으로 TF-IDF 를 활용한 단어 제거, 토픽 분석 결과 맵 시각화 등을 할 수 있습니다. 자세한 내용은 https://cyram.tistory.com/249 를 참조하세요! |
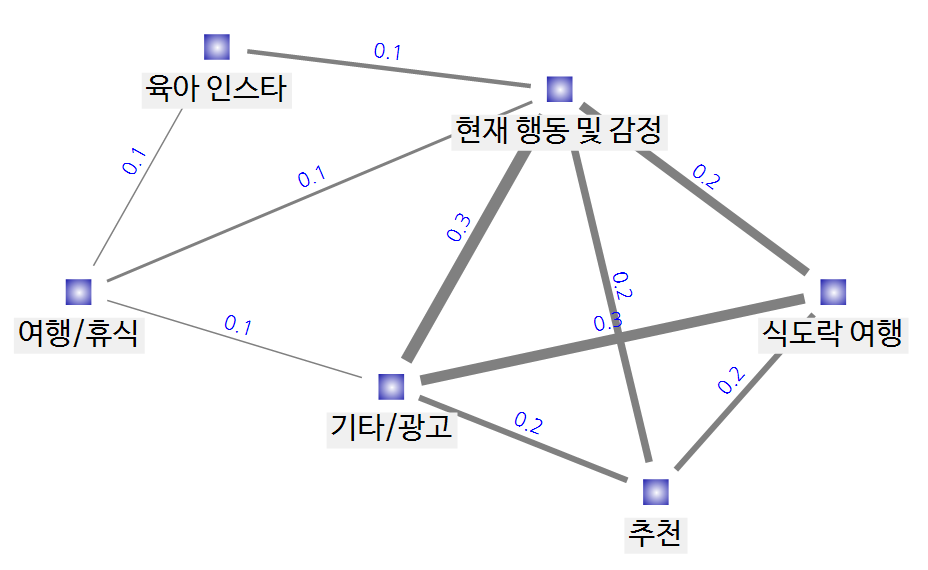
<토픽 간 상관 관계 분석>
토픽 간 유사 정도(토픽 간 상관 관계)도 한 번 확인해 봤습니다.
서로 다른 토픽이 얼마나 유사한 단어를 공유하고 있는지를 측정해보았습니다.
NetMiner 에서 토픽 분석 결과 중 [T] Mainnode Distribution Over Topic 에서 마우스 우클릭 - Add to Workfile - 2 mode network 로 추가합니다.
그리고 Transform >> Mode >> 2-mode network 에서 추가한 단어-토픽 2모드 네트워크를 토픽 간 1모드 네트워크로 변환합니다.
이 때, 토픽 간 링크의 가중치가 바로 토픽 간 유사도(상관 정도) 입니다.
(참고로 모든 단어는 모든 토픽에 대해 Distribution 이 있기 때문에, 토픽별로 Distribution 이 높은 상위 100개 단어만 추출한 후 분석하였습니다)
즉, 토픽 간 유사도가 클수록 두 토픽이 공유하는 단어가 많아서 서로 관계가 더 밀접하다는 의미!
토픽 간 상관 관계를 네트워크 맵과 MDS 로 표현해 보았습니다.
네트워크 맵에서는 선이 두꺼울수록 두 토픽의 유사도가 높음을 의미합니다.
여기까지 NetMiner의 SNS Data Collector 를 활용하여 수집한 인스타그램 데이터의 분석 결과 였습니다.
누구나 할 수 있는 NetMiner를 활용한 소셜 미디어 분석!직접 해보고 싶다면?! |
① NetMiner 홈페이지 에서 누구나 평가판(Trial)을 다운로드 할 수 있습니다.
- NetMiner Free Trial(4주)
- SNS Data Collector(최초 실행 후 7일)
② 사용된 분석 방법은 사이람 온라인 교육센터에서 배우실 수 있습니다.
- NetMiner를 이용한 소셜 네트워크 분석: 네트워크 분석 기초, NetMiner 기초 사용법
- 소셜 미디어 데이터 수집과 분석: SNS Data Collector 사용법 및 소셜 미디어 분석 방법
- 텍스트 네트워크 분석 / NetMiner를 이용한 논문 데이터 수집과 연구동향분석: 토픽모델링을 활용한 텍스트 분석 방법
- 자세한 내용은 사이람 교육센터 를 방문하세요!